
效果展示
先展示一段使用该服务生成的 AI 翻唱
操作前提
需要有腾讯云的账号,没有的话注册一个,可直接使用微信号扫码注册和登录,还是比较方便的。注册地址:https://cloud.tencent.com/login?s_url=https%3A%2F%2Fcloud.tencent.com%2F
方法概述
利用腾讯云每月免费赠送的 10000 分钟 CloudStudio 服务,然后在该服务提供的云端环境中搭建并运行 VITS 项目环境并运行,从而实现 AI 克隆语音和 AI 翻唱。
当然你也可以使用该服务搭建其他 AI 服务,赠送的云端环境配置了英伟达 T4 显卡,16G 显存,可玩性还行。
具体步骤
创建 Cloud Studio 云端环境
打开腾讯云 Cloud Studio 页面,网址:https://ide.cloud.tencent.com/dashboard/gpu-workspace
登录后,在右侧菜单栏选择高性能工作空间,然后选择直接创建
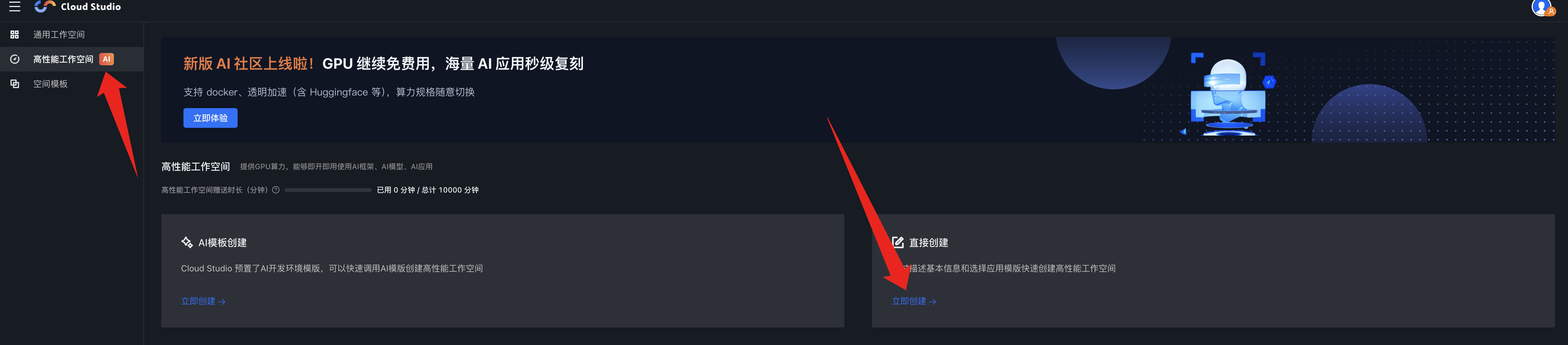
选择免费基础型,然后点新建
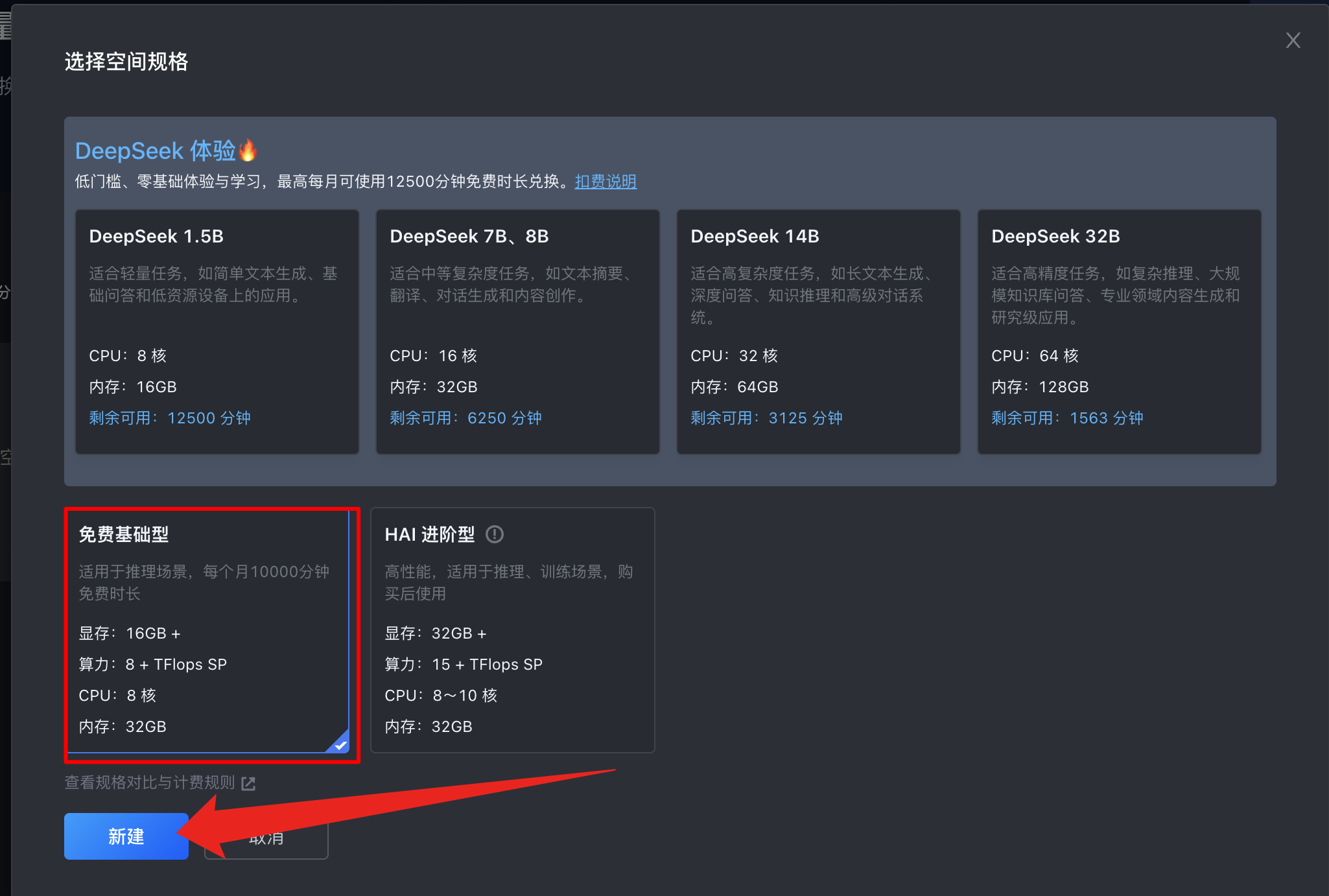
新建空间需要几分钟时间,耐心等待下。启动完成后直接点击进入云环境,可以看出来是个 web 端的 VS Code,Mac 使用 command + J,Windows 使用 Ctrl + J,可以调出终端界面。
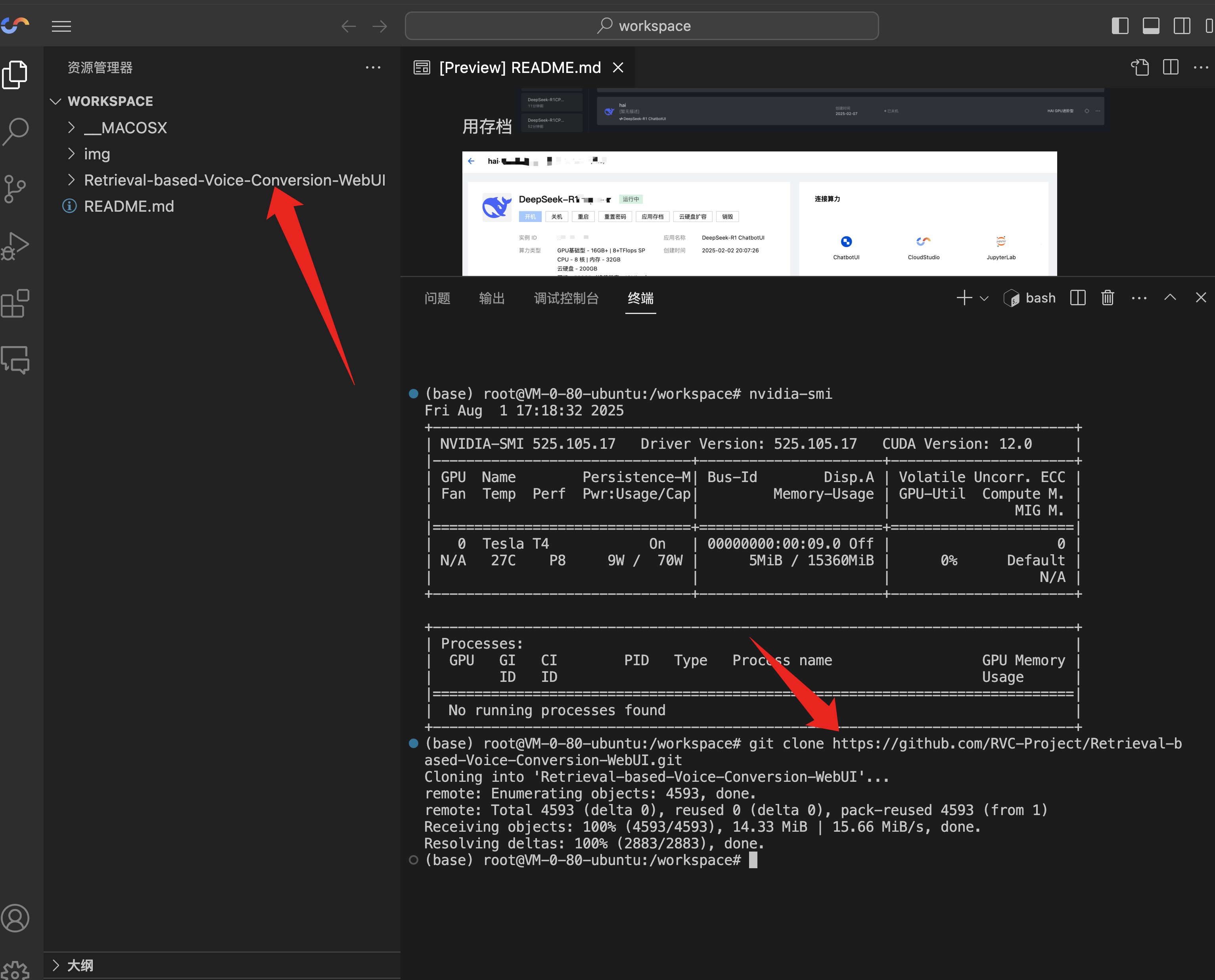
克隆 Retrieval-based-Voice-Conversion-WebUI 项目
你也可以选择其他的 AI 声音克隆项目,例如 GPT-SoVITS、CosyVoice 等等,我这样里使用 Retrieval-based-Voice-Conversion-WebUI,在终端输入命令将项目 clone 到本地。
git clone https://github.com/RVC-Project/Retrieval-based-Voice-Conversion-WebUI.git
clone 完成可以看到,左侧文件树会出现 Retrieval-based-Voice-Conversion-WebUI 项目文件。
创建项目环境并安装项目依赖
CloudStudio 本身已经安装了 Conda 环境,随意可以直接创建一个 Python 3.9 的环境:
cd Retrieval-based-Voice-Conversion-WebUI/ && conda create --name tts python=3.9 -y
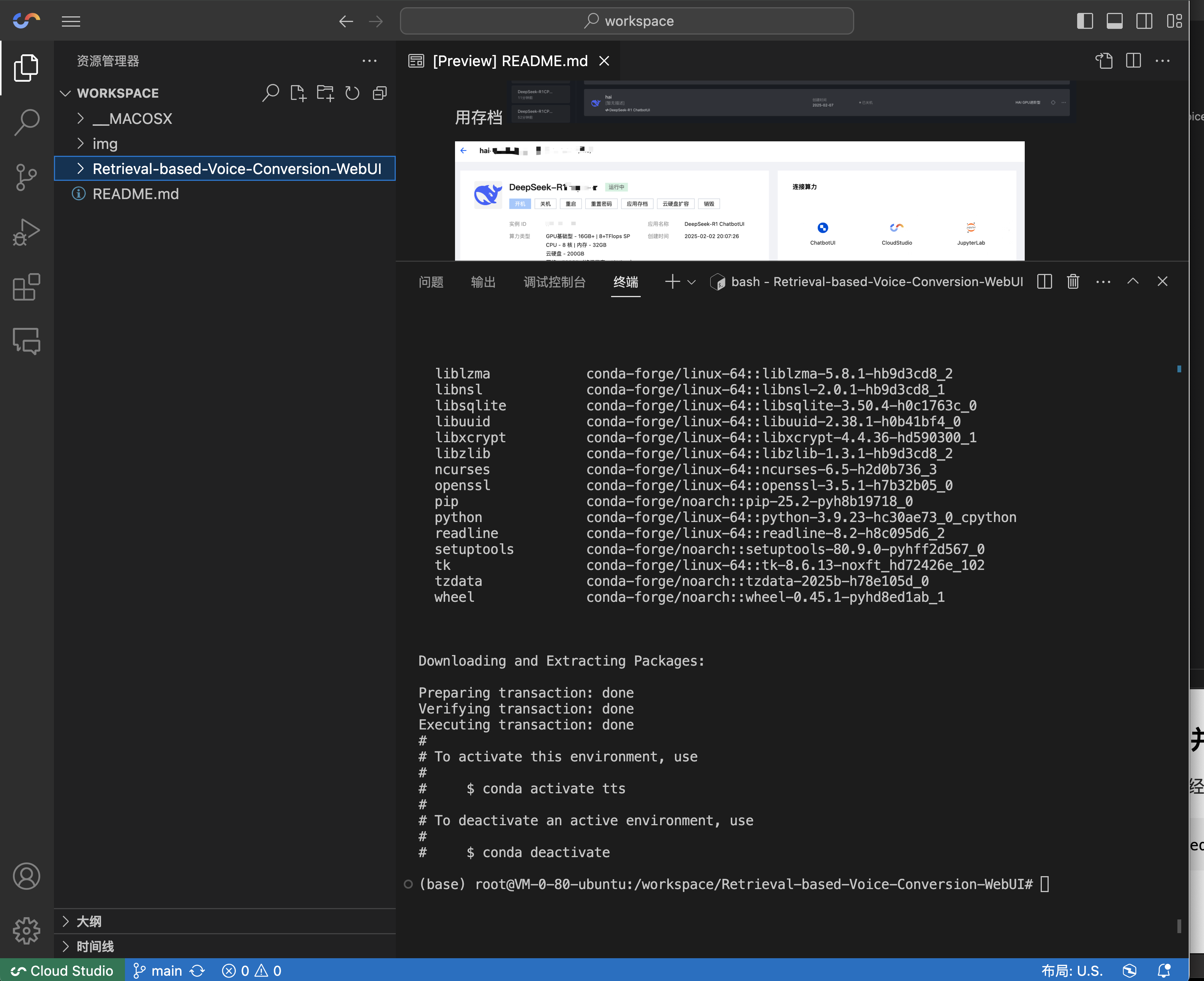
创建完成后,进入虚拟 Python 环境,并安装项目依赖:
## 进入环境
conda activate tts
## 安装 poetry
pip install poetry
修改 requirements.txt 中的项目依赖,删除 aria2:
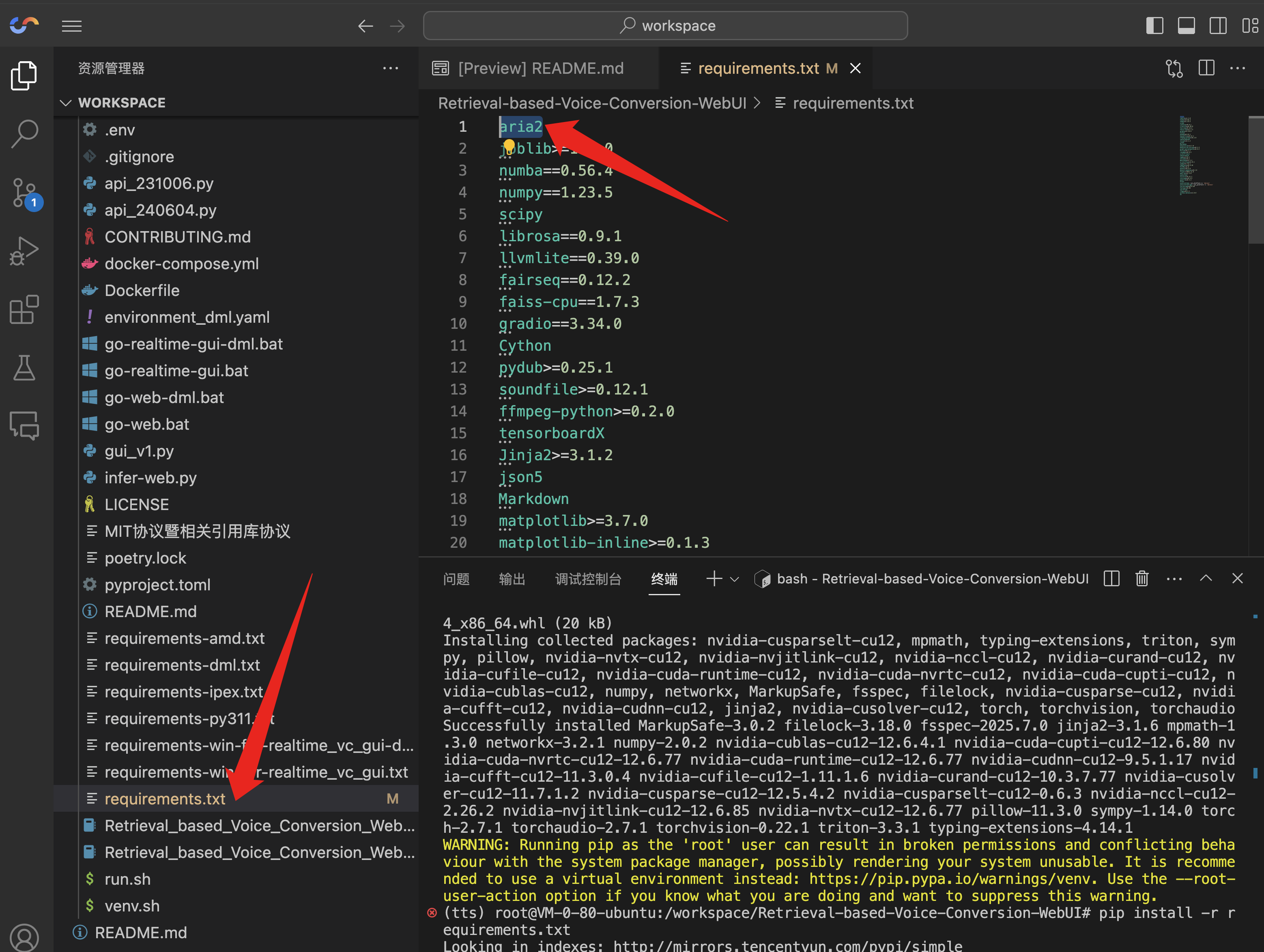
然后安装项目依赖、Pytorch 及其核心依赖:
## 降级 pip 不执行本操作,后续项目依赖会冲突
poetry run pip install "pip<24.1"
## 安装项目依赖
poetry run pip install -r requirements.txt
## 安装 Pytorch 及其核心依赖
poetry run pip install torch torchvision torchaudio
下载模型文件
依赖安装完成后,下载项目所需的模型文件,运行以下命令:
cd tools && python download_models.py
终端输出 'All models downloaded!' 代表模型下载完成。
安装 ffmpeg
执行下面命令安装 ffmpeg,用于音频处理:
apt update && apt install ffmpeg -y
运行项目
所需环境搭建好后,最后就是启动项目了,因为 CloudStudio 环境为提供公网环境,所以这里需要内网传统技术,将项目端口暴露到公网访问,因为该项目使用 gradio,所以我们可以使用 gradio 自带的功能实现,当然你也可以使用其他的服务实现该功能,这里不表。
在左侧文件树找到 infer-web.py 文件,划到最底部,在 'quiet=True,' 后面添加一行,内容为 'share=True':
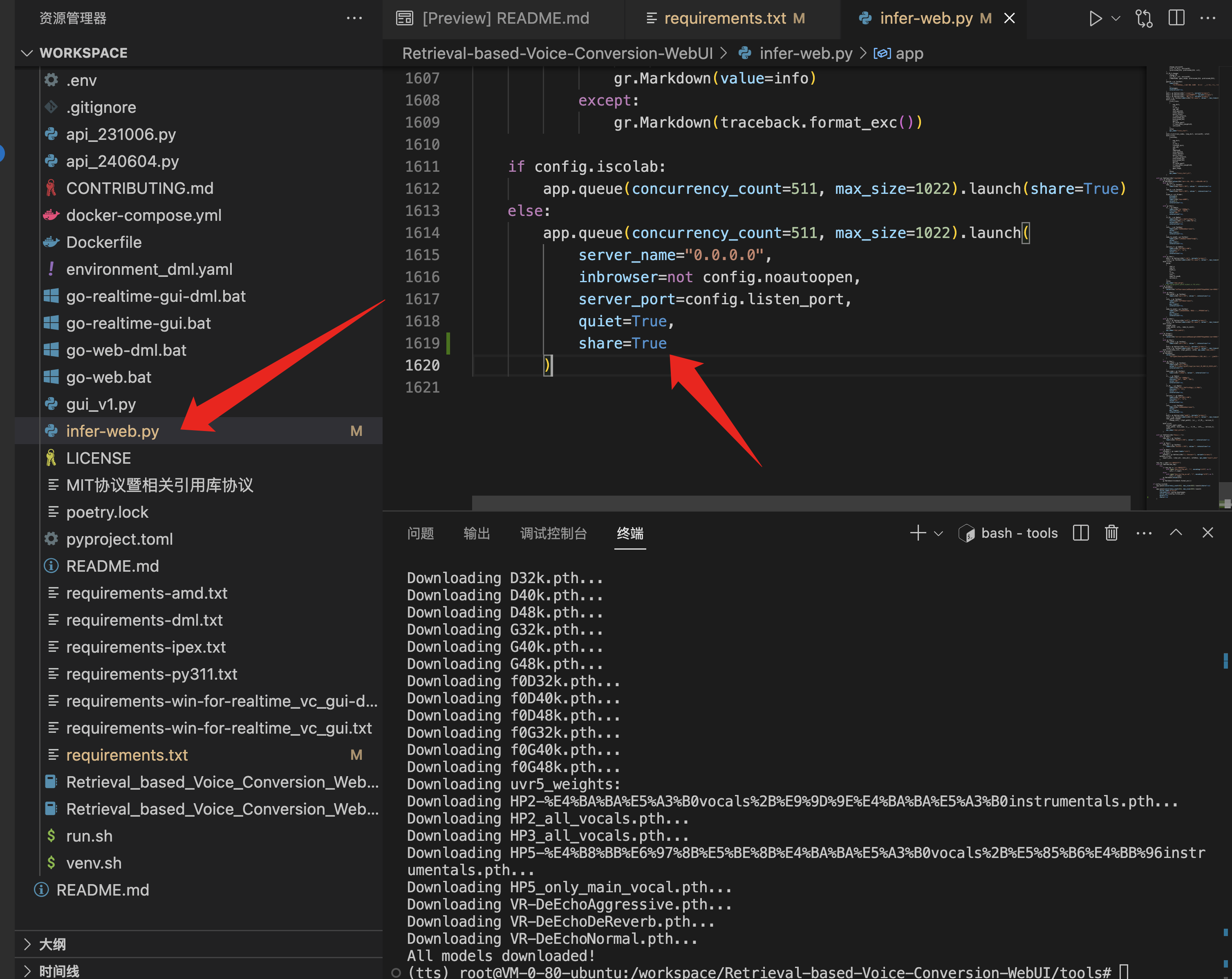
现在运行项目,输入启动命令:
cd .. && poetry run python infer-web.py
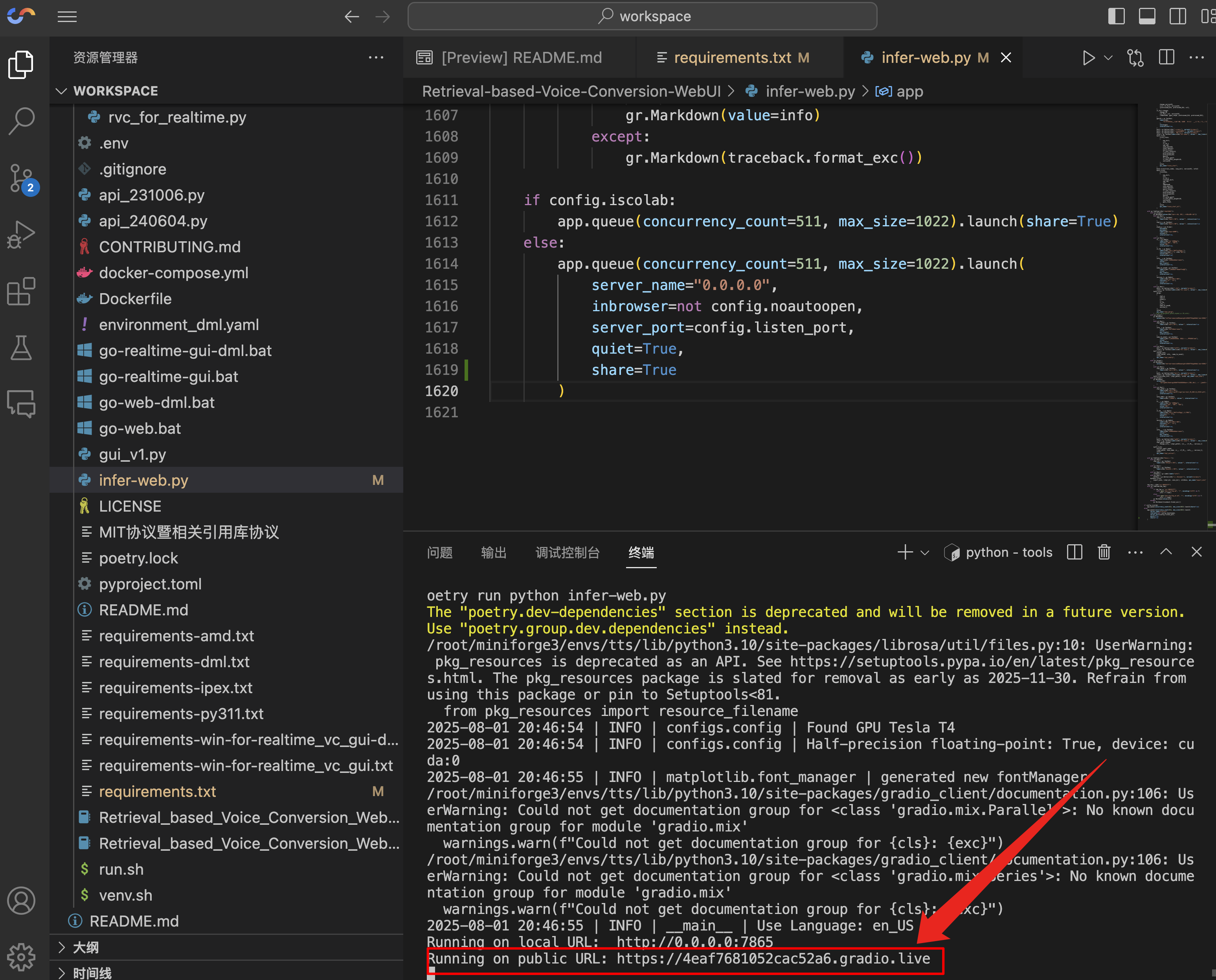
看到箭头指向的 public URL,代表运行成功,复制该链接在浏览器打开
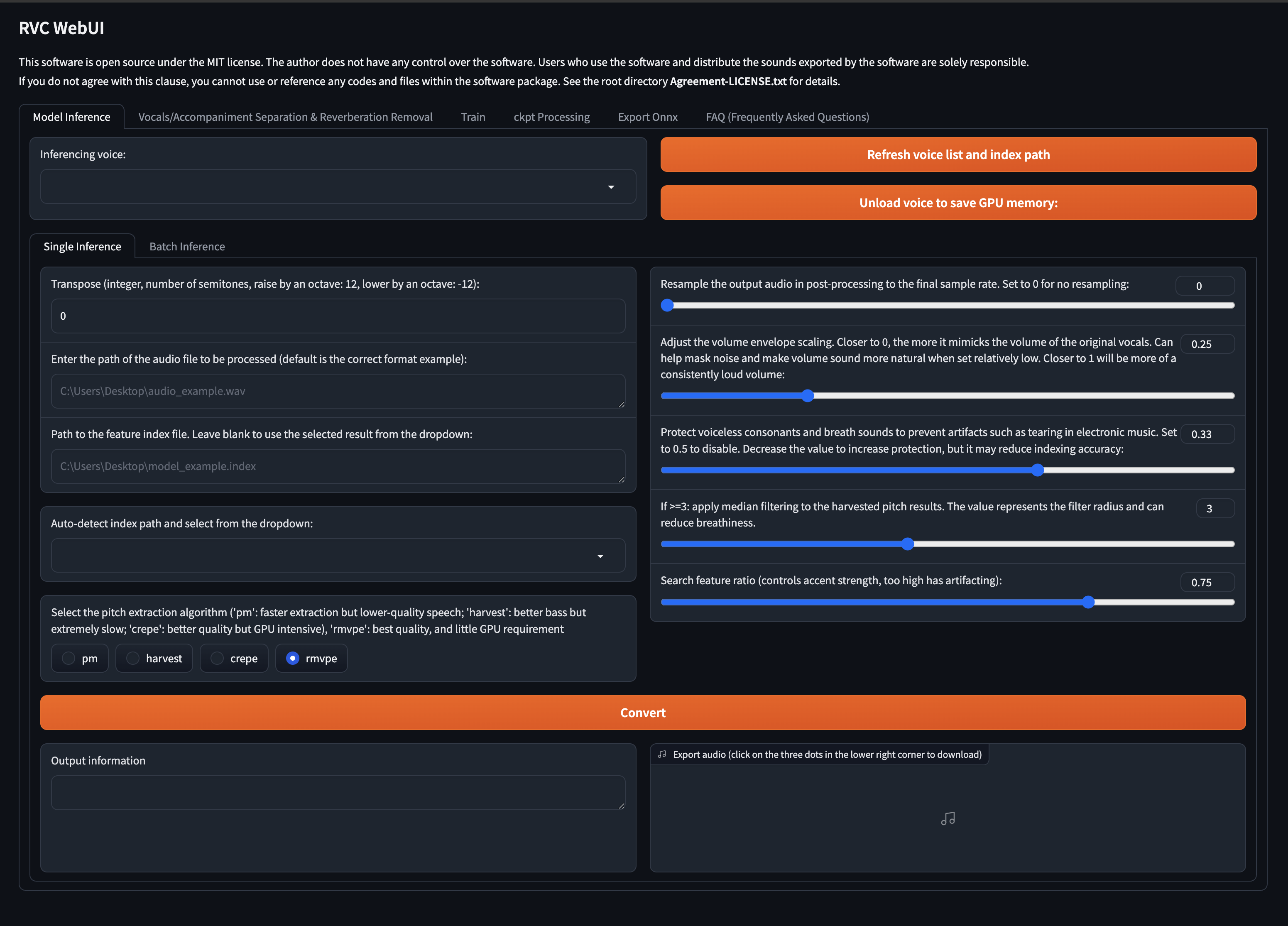
后续的工作就很简单了,上传音频文件训练和推理,这里就不赘述了。难点主要是在 CloudStdio 这套环境中跑通代码
注意事项
gradio 自带的内网穿透的公网链接,可以用来跑接口调用,但是好像有时间限制,过了时间会失效,如果想要一个稳定不变的公网链接,可以使用其他的免费方案。